
🗓️기간
2주차 : 2025.04.14~2025.04.18 ( 4월 3주 )
#. 한 주를 보내며...
강화학습(reinforce,DQN),GAN,전이학습(ResNet),DDP,AutoML에 대해 배우고 2번째 프로젝트를 진행했다. 그동안의 배운 모든것을 통해 분석모델을 만들고 스트림릿으로 시각화 하는 과정이었다.
수업도 항상 좋았지만, 프로젝트를 진행하면서 배운것들을 정확하게 정리하고 구조를 명확하게 할수 있고 5명이서 힘을 합쳐 목표를 만들고 구상해 가는 과정이었다.
1차 프로젝트와 달리 2차에서는 많은 부분에 참여할 수 있었다. 전부 다는 아니지만 과정에 모든 부분에 약간씩 참여하면서 전체프로젝트의 진행을 느껴볼 수 있었다. 기획,데이터분석과 모델구성, 스트림릿 시각화,문서작업에 참여해보면서 전체 개발과정의 로드맵도 느껴볼 수 있었다.
1. 좋았던 점
역시 가장 인상깊은건 프로젝트였다. 첫회의부터 각자의 역할이 명확하게 구분될 수 있었고, 각자의 강점을 통해 프로젝트의 역할분담을 그때그때 유동적으로 바꿔가면서 할 수 있었다. 각자의 강점이 뚜렸했기 때문에 역할 분담시 각자의 강점을 최대한 발휘할 수 있었다.
모델의 성능도 잘 나왔고 팀원의 실력이 좋아 시각화도 상업적인
2. 개선점
전체의 틀을 익히면서 부족한 부분은 AI로 메꾸고 AI로 부족한 부분을 어떻게 메꿀지 알 수 있었고, 지난 과정동안과 앞으로의 과정에서 어떤것에 중심을 잡아야할지 더 명확하게 알 수 있었다.
3. 학습내용 및 예제
1) 수업내용
(1) 강화학습,GAN,전이학습,DDP 정리
| 분야 | 주요 알고리즘 | 환경 | 목적 | 특징 |
| 강화학습 | REINFORCE, DQN | CartPole, BostonHousing | 보상 최대화 | 정책 네트워크, Q-value 기반 학습 |
| GAN | DCGAN | CelebA | 정교한 가짜 이미지 생성 | 생성자-G vs 감별자-D의 경쟁 구조 |
| 전이학습 | ResNet | Fashion MNIST | 적은 데이터로 빠른 수렴 | 사전 학습된 특징 활용 |
| DDP(딥러닝 분산학습) | CNN, RNN, Transformer 등 다양한 딥러닝 모델과 결합 가능한 DistributedDataParallel (DDP) 알고리즘 | PyTorch + GPU 환경 | 대규모 모델/데이터를 병렬 처리하여 학습 속도 향상 메모리 병목 해소 및 GPU 자원 활용 극대화 |
- GPU마다 모델을 복제 후 병렬 처리 |
| (멀티 GPU 서버 / 멀티 노드 지원) | - 데이터는 DistributedSampler로 분산 | |||
| backend='nccl', torchrun, multiprocessing.spawn() 등 사용 | - Gradient는 자동 동기화 | |||
| - 기존 학습코드와 유사하게 구성 가능 | ||||
| - DDP(model) 로 래핑 | ||||
| - 정확도는 단일 모델과 동일하게 유지 |
(2) AutoML 정 ( 모델 선택부터 하이퍼파라미터 튜닝, 앙상블까지 전체 머신러닝 과정을 자동화하는 기술 )
| 분야 | 주요 알고리즘 | 환경 | 목적 | 특징 |
| 회귀/분류/ 시계열 |
LightGBM, XGBoost, CatBoost, RandomForest, Neural Network 등 | Python, AutoGluon, H2O.ai, Google AutoML, Azure ML 등 | 사람 개입 없이 최적 모델 자동 생성 | 데이터 전처리, 모델 탐색, 하이퍼파라미터 튜닝, 앙상블까지 자동화 |
| 비정형 데이터 | CNN, RNN, Transformer, Vision Model 등 | Google AutoML Vision, AutoKeras 등 | 이미지/텍스트 자동 분류 | 모델 구조 탐색(NAS), 정규화, augmentation 등 포함 |
| 구조적 데이터 | GradientBoosting, ExtraTrees, VotingClassifier 등 | AutoGluon, H2O.ai, MLJAR, TPOT | 정형 데이터 예측(이탈, 수요, 매출 등) | 지도/비지도 학습 모두 지원, 다양한 모델 비교 가능 |
| 하이퍼튜닝 | Bayesian Optimization, Grid/Random Search, Hyperband 등 | Optuna, Ray Tune, AutoGluon 내부 | 최적 성능을 위한 파라미터 자동 탐색 | 리소스 절약, 성능 향상, 사용 편의성 높음 |
| 앙상블 모델링 | Stacking, Blending, Weighted Voting | AutoGluon, H2O AutoML, MLJAR 등 | 여러 모델 결합으로 일반화 성능 향상 | 과적합 방지, 다양한 예측 결과 융합 가능 |
2) 프로젝트
Kaggle의 E-commercial 데이터를 가져와서 전처리 후 머신러닝모델로 분석하여 xgboost모델을 선택하고streamlit으로 인터페이스를 구성하여 데이터 분석 프로그램을 제작하였다.
분석프로그램의 목표는 고객의 패턴을 분석하고 이탈 가능성이 높아지는 고객에게 맞춤혐 솔루션을 제공하여 이탈을 방지하는것이다. 이를 실행하기 위해 이탈율을 분석할 수 있는 데이터를 통해 상관관계를 파악하고 각 상관관계에서 어떠한 데이터가 이탈에 가장큰 영향을 미치는지 파악하고 솔루션을 제공하여 이탈을 막는것을 목표로 하였다.
#. kaggle에서 기존 데이터를 가져와 데이터분석부터 실시하였다.
#. 사용한 라이브러리

(1) 데이터 분석 - 데이터 연관성 및 이상치 분석



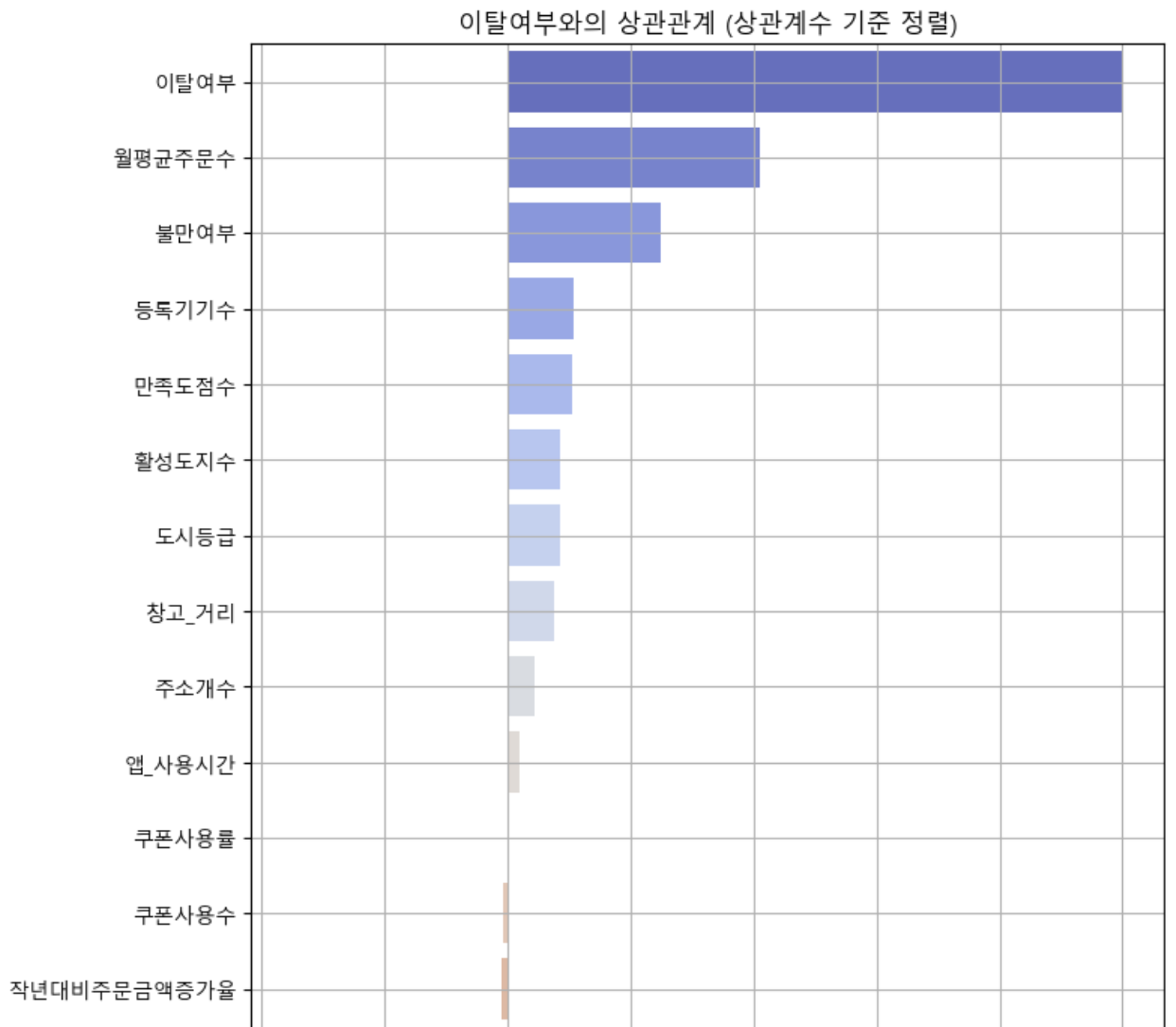
# 데이터 분석이 끝난후에는 데이터 전처리를 진행하였다(결측치처리, 이상치 제거,원핫인코딩)
(2) 데이터 전처리


(3) 데이터 전처리 후 12개 모델 일괄 테스트


(4) Streamlit으로 인터페이스 작업 및 데이터 분석 테스트 ( 구현모델 일부 기능 )
- 위험변수 변경시 위험도 급격한 감소 확인


(5) 분석모델 평가




4. 9주차의 목표
RAG+LLM의 전과정을 완벽히 마스터 하자
'[ 플레이데이터 SK네트웍스 Family AI 캠프 ]' 카테고리의 다른 글
| [플레이데이터 SK네트웍스 Family AI 캠프 12기] 10주차 회고 (0) | 2025.04.28 |
|---|---|
| [플레이데이터 SK네트웍스 Family AI 캠프 12기] 9주차 회고 (0) | 2025.04.25 |
| [플레이데이터 SK네트웍스 Family AI 캠프 12기] 7주차 회고 (0) | 2025.04.12 |
| [플레이데이터 SK네트웍스 Family AI 캠프 12기] 6주차 회고 (0) | 2025.04.06 |
| [플레이데이터 SK네트웍스 Family AI 캠프 12기] 5주차 / 1달 회고 (0) | 2025.03.29 |