
🗓️기간
15주차 : 2025.06.02~2025.06.05 ( 6월 1주 )
#. 한 주를 보내며...
4월부터 시작했던 3번째 커리큘럼의 교육이 모두 끝나고 6월2일부터 3번째 프로젝트가 시작되었다. RAG시스템 기반의 llm챗봇 구축은 부트캠프오기전에 가장 관심있었던 분야였다. 하지만 프로젝트 시작전에는 한달반동안 수업을 제대로 못따라가고, 이해하지 못하는 부분이 많아서 제대로 할 수 있을까 걱정이 많았다.
역시나 프로젝트를 시작하자마자 단어나 표현,구현방법에 대해서 팀원들과 의사소통에 문제가 발생하고 조율이 잘 안 되었지만 몇 시간동안 회의를 진행하면서 각자 배우고 이해했던 파트를 논의하니 조립이 잘 안되고 추상적으로 알던 개념들이 하나씩 맞춰지기 시작했고, 계획이 어느정도 잡히고 제작을 시작했다. 작업하는동안 잘 이해되지 않던 부분이 하나하나 이해되면서 전반적으로 이해할 수 있었다.
처음 부트캠프에 왔을때는 내가 이정도로 개발할 수 있을거라고는 생각하거나 예상하지도 못했다. 1차 프로젝트에서 겨우 크롤링만 했었지만, 3차가 되니 전체적인 구성을 계획할수 있고, 코드와 모듈도 세부적으로 만들 수 있을정도로 발전했다.


1. 좋았던 점
프로젝트 시작전에는 RAG 시스템 구축할때 랭체인,벡터DB만들기,청크,임베딩,데이터 전처리 등 각각의 단계에서 어떤걸 해야 할지 대략적으로는 알고 있었지만 구체적으로 이걸 어떻게 조립해야하는지, 각각은 어떻게 연동해야 하는지 헷갈리는 부분이 많았었다. 그러나 프로젝트 동안 랭체인호출-llm호출-벡터db연동의 기본구조에 대해 정확하게 이해할 수 있었고, 해보고 싶었던 Function_calling기능과, langchain agent의 hybrid search기능과 네이버API연동을 구현해서 자연어 질문이 들어왔을때 벡터DB의 내부자료-네이버검색-툴호출이 연속적으로 구성되게 한점은 좋았다.
2. 개선점
용어의 정립과 자연어질문 - 벡터라이징 - llm추론 - 자연어답변이 되는 과정을 이해하고 langchain agent까지 구성하고 순서도를 정확하게 이해할 수 있었다.
팀원들과의 호흡도 좋았고, 각자 맡은 부분의 완성도가 높아지면서 다른파트도 그에 맞춰 완성도를 높히다 보니 전체적인 완성도가 매우 높아졌다. 특히 깃허브작업을 나눌때 모듈단위로 나누어서 작업하니 충돌걱정없이 각각의 역할에 충실할 수 있었다.
이전에는 프로그램구성때 오류없이 코드가 실행만 되면 된다 라는 개념이었지만 이번에는 전체 로직과 코드의 구조와 역할,연결고리를 고려해서 각각을 모듈화해서 연결하는 구조로 설계했다. 확장성도 고려해서 확장 가능한 구조로 구성하고 각각의 파일이 상호작용할 수 있도록 했다.

app.py ---> agent_excutor.py <---> rag_tool.py 로 과정이 이어지도록 구성하였고 각 과정에 새로운 모듈을 추가할 수 있도록 구성하였다. 새로운 기능을 추가할때는 agents/tools에 새로운 모듈만 추가하면 되고, 벡터db도 data에 계속 폴더를 추가하여 벡터db업데이트의 확장성을 높혔다.
3. 아쉬운점
수업중에 진행했던 최신 기법인 runnable agent와 lang-graph로 구현하지 못한것은 아쉬웠다. 마지막 프로젝트에는 runnable agent, lagn-graph, mcp 연동을 전부 학습해서 적용하는 목표가 생겼다. 프로젝트때는 그동안 배운내용을 총정리하고 수업내용을 나만의것으로 만드는 과정과 부족한부분이 어떤건지, 앞으로 개발해야 하는 내 필수역량이 무엇인지도 알게 되는것 같다.
4차 프로젝트 전까지 3가지를 더 개발해야 하는 3가지가 생겼다. 먼저 깃허브를 더 공부하여 브랜치로 각각의 작업을 나눌 수 있도록 배우고, 두번째로 RAG시스템의 완성도를 높히기 위해 lang-graph,mcp구성방법, 마지막으로 작업보고서작성 방법까지 더 발전시킬 계획이다.
4. 배운점
# 프로젝트 과정 및 결과
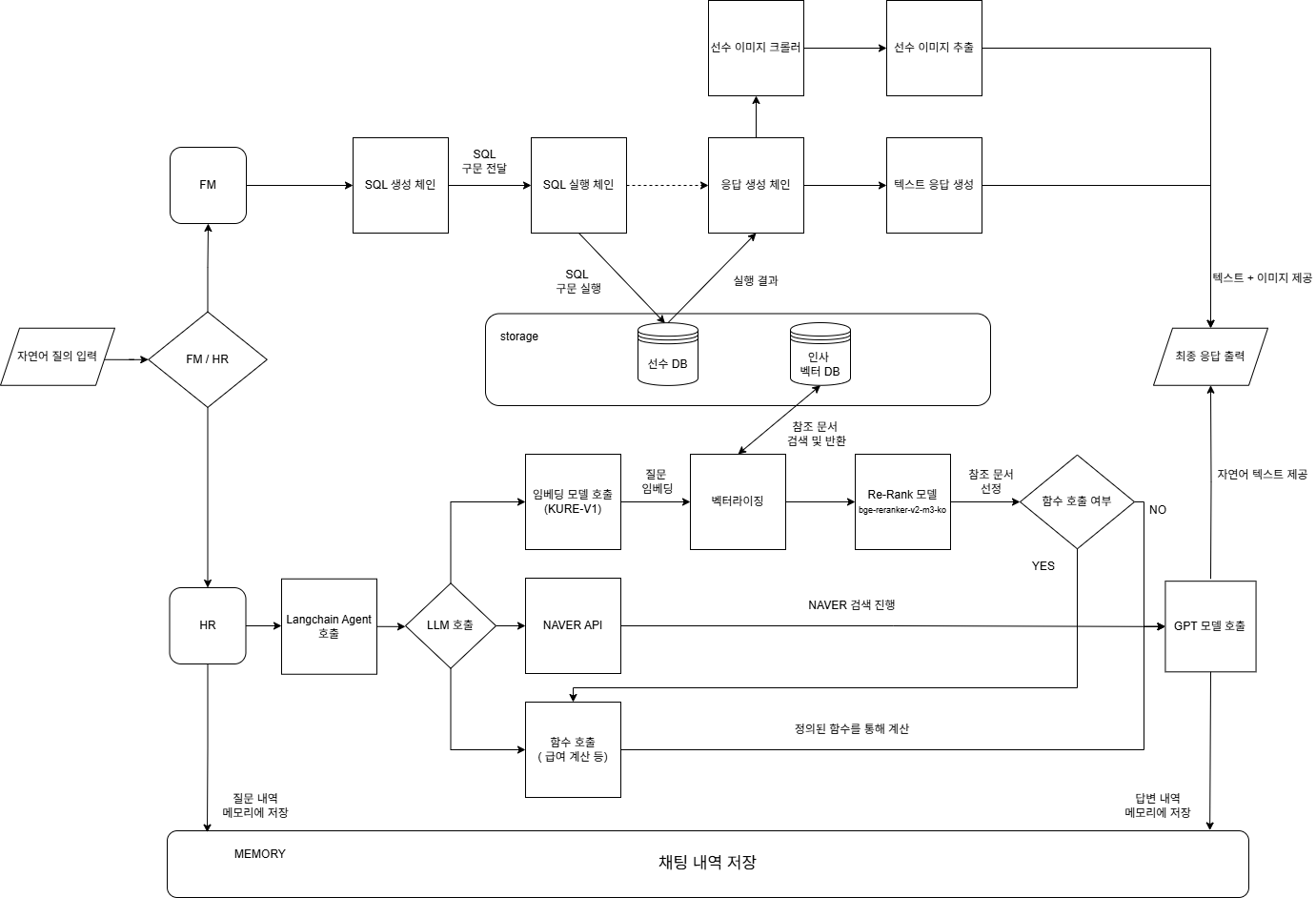
프로젝트 3차 프로젝트는 축구선수만 전문적으로 다루는 스포츠 에이전시에서 사용할 수 있는 챗봇을 만들었다. 첫 구상부터 기능은 크게 2가지를 고려해서 제작했다. 축구선수의 자세한 데이터와 각각의 정보를 분석해주는 LLM과 내부데이터와 외부의 최신정보도 검색할 수 있는 프로그램이었다. 처음에는 각각의 기능을 탭을 나눠가며 사용할 수 있는 LLM을 생각했으나, 회의를 하면서 라우터 기능으로 축구선수 분석 / 내부자료 검색을 하나의 채팅창에서 구현하기로 했다. 먼저 축구선수 데이터는 FM 2023이라는 8400명의 축구선수 데이터를 공격력,왼발,속도,판단력 등등 다양한 세부점수가 있는 테이블 데이터 였고, 내부자료는 필드에서처럼 현실적으로 만들기 위해 복잡한 3가지 형태의 데이터를 사용했다. 표,숫자,글자가 섞여있는 혼합형데이터,테이블데이터,특수문자로 조직구조를 표현한 조직도 였다. 시간이 부족했기 때문에 각각의 파트를 나눴고, 나는 RAG시스템을 담당하기로 했다.

다양한 데이터와 수업에서 배운내용을 모두 적용해보기로 했고 각자 맡은 부분에서 계획보다 더 높은 성과를 내서 빠르게 합치고 발표까지 빠듯한 일정이었지만, 결국 계획대로 제작했다. 내가 담당했던 RAG 시스템은 이 3가지 복합적인 데이터를 벡터DB로 임베딩 하고 사용자가 자연어로 질문을 하면 llm이 벡터DB에서 검색해서 답변을 만들어 주는 단순한 형태를 보다 발전시켰다. 사용자 질문이 분류기를 통해 내부분서 HR모듈로 전달이 되면 langchain agent에서 시작하도록 구성하였다. langchain agent는 llm을 호출하여 다시 질문에 따라 3가지가 순차적으로 작동하는 hybrid search 방식으로 구성하였다. 먼저 내부분서에 해당되는 정보일 경우에는 벡터DB에 접속해서 내부문서에 해당되는 답을 주고, 그게 아닐경우에는 미리 연동해둔 네이버 api를 통해 네이버 검색결과와 출처를 보여주게 설정하였다. 그리고 function calling 기능도 추가하여 계산식이 필요할 경우에 @tool에서 필요한 함수를 호출하여 추론이 아닌 정해진 계산식에 맞춰 계산하도록 하였다. 환각현상을 줄이고 정확도를 높히기 위해 리랭커 모델도 추가하였다. 답변시 내부문서인 벡터DB에서 답변 메세지를 만들때에 임베딩모델이 먼저 10개의 유사한 문장을 찾고 이후에 바로 llm으로 전달하는것이 아닌 다시 리랭커 모델이 3개로 추려서 llm에 전달하도록 하였고 정확도가 많이 향상되었다.

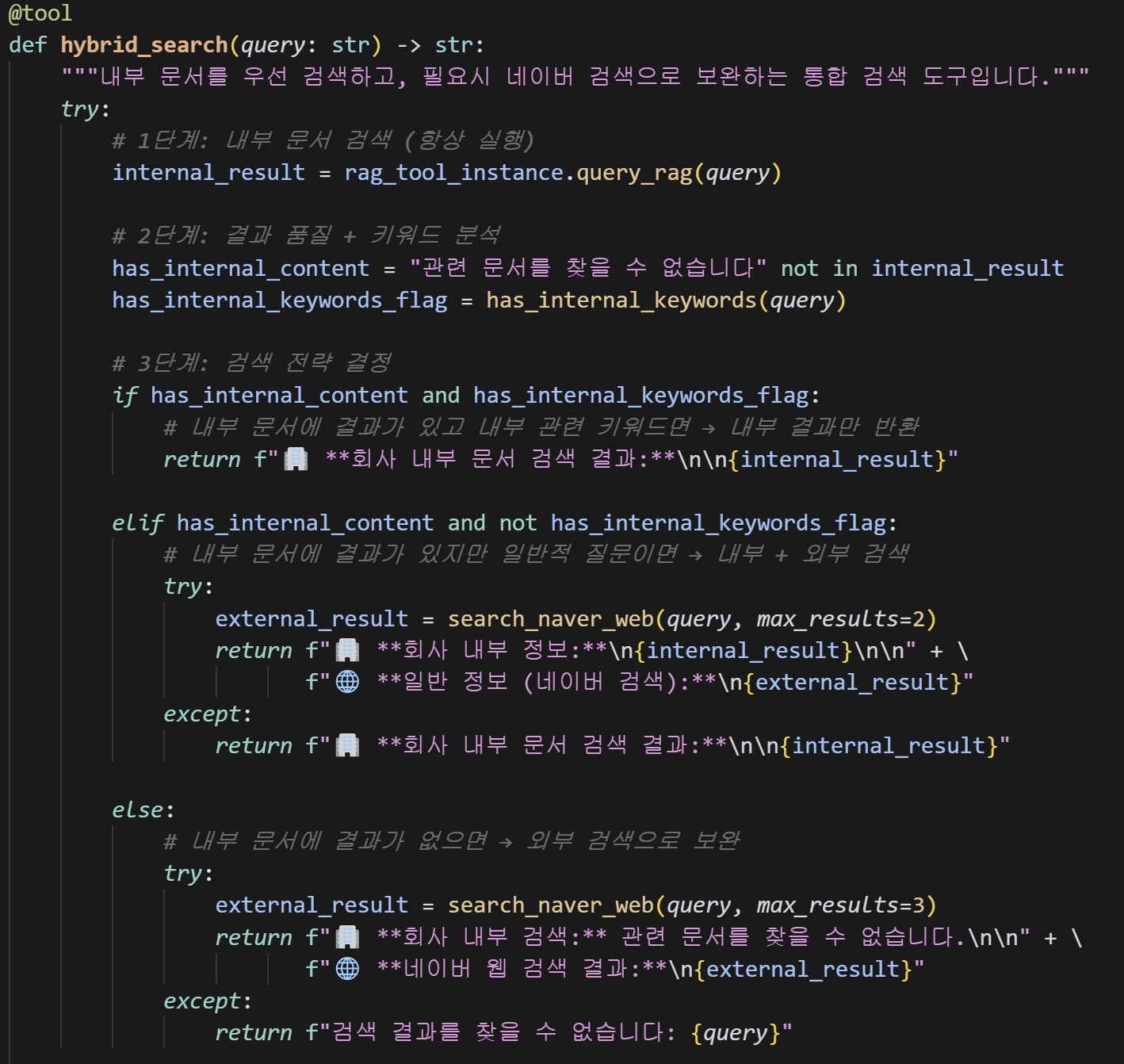


내부문서 검색시에 내부문서가 아닐경우에는 연동된 네이버api와 연동해서 답변을 얻도록 설정했다. 처음 제작부터 각각의 파일을 모듈화해서 확장성을 가질려고 계획했다. langchain만을 바꿀려면 agent파일만 수정하면되고 벡터 db추가는 data폴더에 추가, 기능추가는 tool에 계속 추가하면 되도록 구성했다. 벡터db는 2가지로 나누어서 작업하였다. 먼저 복합데이터인 내부문서는 기존의 데이터를 먼저 청크하기 좋게 필요없는 내용 ( 목차, 의미없는 기호 )을 제거하고 청크를 진행 후에 정확도를 더 높히기 위해 청크보완을 진행하였고, 검색시 중요내용이 누락되지 않도록 슬라이딩윈도우 방식으로 하였다. 슬라이딩 윈도우 방식은 조단위로 나눈걸 3개씩 겹치도록 구성하였다. 내부규정은 답변처리 속도보다 누락없이 내용이 정확하고 환각현상이 발생하지 않는 것이 중요하기 때문에 이 방식으로 청크보완 하였다. 인사정보는 기존의 인사정보와 조직도를 매칭하여 청킹하였다. 이후 임베딩은 kure-v1이라는 bge-m3를 고려대학교에서 한국어 성능을 더 향상시켜 튜닝한 모델을 사용하였다. 정확도를 더 높히고 환각현상을 줄이기 위해서 프롬프트도 여러가지로 테스트 해봤다. 역시 프롬프트 마다도 성능이 다 달랐고 금지형 프롬프트가 가장 점수가 높았다. 답변 생성시에도 리랭커 모델을 추가하였다. 임베딩모델이 벡터DB에서 답변을 10개를 가져오면 리랭커 모델이 다시 상위3개로 요약해서 llm에 전달하도록 했고, 추후 점수나 정확도 테스트에서도 20%이상 향상되는 결과를 보여줬다. 리랭커 모델은 bge-reranker-ko모델로 임베딩 모델고 같은 bge 계열이고, 다시 한국어정확도를 높힌 모델이다.

2차때 깃허브데스크탑을 통해 팀프로젝트 하는방법은 알았지만, 내가 main 브런치를 구성해서 진행하는건 처음해봐서 좋았다. 팀원들의 이해로 마지막 보고서 작성과 깃허브 구성도 해보았는데 배운점이 많았다. 특히 프로젝트 결과 보고서와 readme파일을 마지막에 작성했는데, 개발시 보고서 작성을 고려하지 않고 코드를 지저분하게 만들어서 마지막에 정리할때 고생을 많이 했다. 다음 작업과 4차 작업때는 결과 보고서 작성을 어떻게 할지 염두해두고, 작업시 중간중간 업데이트 하는 방식으로 작성 할 계획이다.
5. 16주차의 목표
백엔드의 시작이다. 수업내용 학습시 4,5차때 어떻게 적용할지 뿐만 아니라 앞으로 부트캠프이후에도 내가 어떻게 활용할지 생각하면서 공부할 계획이다.
rag 심화과정으로 개인적으로 lang-graph구성을 공부해서 이번 프로젝트에서 구성했던 방식을 lang-graph로 다시 구현하고 개선시킬 계획이다.
'[ 플레이데이터 SK네트웍스 Family AI 캠프 ]' 카테고리의 다른 글
| [플레이데이터 SK네트웍스 Family AI 캠프 12기] 16주차 회고 (0) | 2025.06.16 |
|---|---|
| 플레이데이터 SK네트웍스 Family AI 캠프 12기] 14주차 회고 (1) | 2025.06.08 |
| [플레이데이터 SK네트웍스 Family AI 캠프 12기] 13주차 회고 (1) | 2025.05.24 |
| [플레이데이터 SK네트웍스 Family AI 캠프 12기] 12주차 회고 (0) | 2025.05.17 |
| [플레이데이터 SK네트웍스 Family AI 캠프 12기] 11주차 회고 (5) | 2025.05.12 |